Basisterminologie der Korpuslinguistik
Primärdaten
- Primärdaten können entweder von Anfang an digital sein (born-digital, z. B. Video, Audio, digitale Texte) oder nachträglich digitalisiert werden (z. B. handschriftliche Aufsätze).
- Primärdaten als Korpusgrundlage: Aufnahmen und Antworten aus offenen/semi-strukturierten Interviews, Fragebögen sowie Beobachtungsaufzeichnungen können ein Korpus bilden.
- Korpora enthalten Primärdaten nie vollständig „originalgetreu“: Durch technische Vorverarbeitung und je nach Fragestellung werden bestimmte Eigenschaften weggelassen.
- Beispiel für Reduktion: Typografische Merkmale wie Fett- oder Kursivdruck können entfernt werden, wenn sie nicht relevant sind.
- Korpora sind meist umfangreiche Datensammlungen und ermöglichen quantitative Analysen.
- Es gibt keine Mindestgröße für ein Korpus: Es kann sehr klein (z. B. 100 Dokumente) oder sehr groß (z. B. drei Millionen Dokumente) sein.
- Die Korpusgröße hängt vor allem von der Fragestellung und der Datenverfügbarkeit ab.
(Studienbuch Linguistik: 633-634)
Metadaten

- Metadaten sind Daten über die Primärdaten im Korpus und beschreiben diese systematisch und einheitlich (für alle Dokumente gleich).
- Beispiele für Metadaten: Urheber:in, Erstellungsdatum, Zuordnung zu Klassifikationen (z. B. Textsorte).
- Der Begriff „Dokument“ ist weit gefasst: einzelne Einheiten eines Korpus, die je nach Fragestellung als abgeschlossen gelten (z. B. Online-Artikel, Parlamentsrede, Gespräch, YouTube-Kommentar).
- Für die Erfassung von Metadaten sollen idealerweise wissenschaftliche Standards genutzt werden – sowohl für welche Metadaten erfasst werden als auch für deren Benennung.
- Standards machen Korpora vergleichbarer und leichter teilbar (Interoperabilität), weil Konventionen in der Community bekannt sind.
- Beispiel für Standardisierung: XML-Header nach den Konventionen der Text Encoding Initiative (TEI).
- Metadaten erlauben, ein Korpus in Untergruppen zu zerlegen (nach einem oder mehreren Metadaten), z. B. Gruppierung nach Jahr über das Metadatum
<date>. - Dadurch werden Gruppenanalysen und Vergleiche möglich (z. B. Trends wie „Phänomen xy stieg 2005–2023 um 40 %“).
- Insgesamt: Metadaten ordnen und sortieren Korpusdokumente flexibel und unterstützen Auswertungen.
Annotation
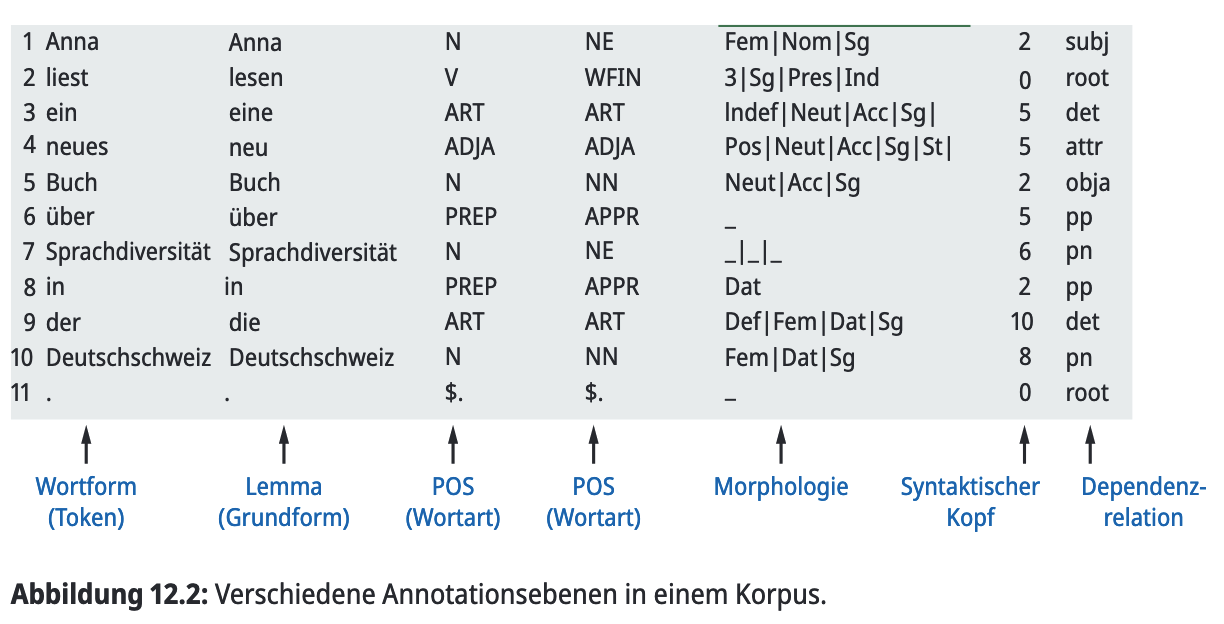
- Neben Primärdaten und Metadaten sind Annotationen ein zentraler Bestandteil von Korpora.
- Annotationen sind linguistische Merkmale, die sprachlichen Einheiten innerhalb von Korpusdokumenten zugewiesen werden.
- Annotiert werden können unterschiedliche Einheiten: Wörter und Mehrworteinheiten, Konstituenten, Sätze, aber auch Morpheme oder größere Textabschnitte.
- Für gut erforschte Sprachen wie Deutsch werden Annotationen häufig automatisiert erzeugt.
- Dieser Prozess heißt Tagging: Einheiten erhalten Tags, z. B. zur Wortart eines Tokens.
- Wortarttagging wird auch POS-Tagging genannt (POS = Part-of-Speech).
- Die Genauigkeit automatischer Annotationen und die Fehlerquote hängen von der jeweiligen Annotationsebene ab.
- Es gibt verschiedene Annotationsebenen (siehe Abbildung).
Annotationsebenen
- Tokenebene: Text wird in Tokens zerlegt (meist Wörter; auch Satzzeichen und Zahlen zählen). Das heißt Tokenisierung und ist die Basis für viele weitere Annotationen – Fehler hier ziehen Fehler bei POS/Syntax nach sich.
- Lemmaebene: Jedem Token wird die Grundform zugewiesen (Lemmatisierung). Automatisch oft über Lexika; unbekannte Wörter bleiben sonst meist als Token selbst stehen.
- POS-Ebene: Jedem Token wird eine Wortart zugeordnet (POS-Tagging) anhand von Tagsets. Beispiele: UPOS (grob) vs. STTS (feiner, viele Tags).
- Morphologieebene: Annotation von grammatischen Merkmalen (z. B. Numerus, Tempus, Genus). Hängt oft am selben Lexikon wie die Lemmatisierung; bei unbekannten Wörtern fehlen Angaben.
- Syntaktische Ebene: Für jedes Token werden syntaktischer Kopf und Dependenzrelation angegeben (z. B. Subjekt–Verb). Dafür werden oft automatische Parser eingesetzt.
- Qualität automatischer Tagger variiert je nach Ebene, Domäne und Sprache: Für schriftliches Standarddeutsch ist POS-Tagging sehr zuverlässig (z. B. TreeTagger >96% laut Schmid 1994), für gesprochene Sprache meist deutlich schlechter, weil viele Tools auf Standardschriftdeutsch trainiert sind.
(Studienbuch Linguistik: 635-637)
Beispiele für automatischer Tagger
- TreeTagger für verschiedene Sprachen: https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/
- Hier kann man den TreeTagger online ausprobieren: https://cental.uclouvain.be/treetagger/
- Stanford Tagger online: https://parts-of-speech.info
- Parsing/Tagging:
- Stanza Tagger/Parser: https://stanfordnlp.github.io/stanza/
- Online: http://stanza.run
- SpaCy: https://spacy.io
- Weitere Online-Demos: https://explosion.ai/software
Korpustypen

Treffgenauigkeit
Bei einer Suche in einem Korpus stellt sich immer die Frage, ob mit der Suchanfrage (Query) auch tatsächlich die gewünschten Belege (Ergebnis) gefunden werden. Dabei muss man zwei Perspektiven unterscheiden:
- Präzision: Sind alle Treffer in der Ergebnismenge gewünschte Treffer?
- Ausbeute / Recall: Habe ich alle Treffer, die im Korpus sind, erwischt?
Beispiel: Wir möchten Verbzweitstellung im Nebensatz (Phänomen) in einem Korpus von Texten finden und nutzen eine bestimmte Suchanfrage (Query) dafür. Präzision: Wieviel Prozent aller Treffer sind tatsächlich Beispiele für das gewünschte Phänomen? Ausbeute: Wieviel Prozent aller im Korpus vorhandenen Fälle habe ich mit meiner Query gefunden?
Die Präzision der Suchanfrage ist viel einfacher zu kontrollieren: Im Prinzip kann man einfach die Belege darauf hin überprüfen, ob es sich um gewünschte Belege handelt. Wenn nicht, dann kann die Suchanfrage entsprechend angepasst werden.
Die Ausbeute ist weniger gut kontrollierbar: Dafür müsste ich die ganze Datengrundlage kennen und abschätzen können, ob ich alles, was ich eigentlich finden will, in der Ergebnismenge hat. Das kann man bei einem Korpus natürlich normalerweise nicht. Eine mögliche Strategie ist, testweise die Suche etwas weniger präzis zu formulieren (dabei sinkt also die Präzision), um eine möglichst grosse Ausbeute zu erhalten. Dann kann man die Suchanfrage wieder präziser gestalten und darauf achten, ob die gewünschten Treffer noch immer vorhanden sind.
Daraus ergeben sich dann die folgenden Klassen von korrekten und falschen Treffern:
- Positiv = Fall ist das gewünschte Phänomen, z.B: Es liegt Verbzweitstellung im Nebensatz vor.
- Negativ = Fall ist nicht das gewünschte Phänomen, z.B.: Keine Verbzweitstellung im Nebensatz.
Daraus ergibt sich:
- Richtig positiv (True Positive, TP): Query findet einen Treffer und es ist tatsächlich V2 im Nebensatz.
- Falsch positiv (False Positive, FP): Query findet einen Treffer, aber es ist keine echte Verbzweitstellung im Nebensatz (Fehlalarm).
- Richtig negativ (True Negative, TN): Query findet keinen Treffer und es liegt tatsächlich keine V2 im Nebensatz vor.
- Falsch negativ (False Negative, FN): Query findet keinen Treffer, aber es gibt tatsächlich V2 im Nebensatz (übersehen).
Konkordanz / KWIC, Keyword in Context
Die Analyse von Konkordanzen (oder auch Keywords in Context, kurz KWIC): Damit ist eine spezielle Darstellungsform gemeint, bei der ein im Korpus gesuchtes Wort in seinem unmittelbaren Kontext dargestellt wird. Jede Fundstelle steht in einer separaten Zeile. Durch das Sortieren von Fundstellen basierend auf dem Kontext lassen sich Musterhaftigkeiten im Gebrauch eines Wortes erkennen. Abbildung 12.8 zeigt das exemplarisch für das Wort Freiheit im DWDS, sortiert nach dem ersten Wort im rechten Kontext. Durch die Sortierung werden Aufzählungen mit Freiheit sichtbar (z. B. Demokratie, Freiheit, Respekt).

Korpusgrössen
Eines der bekanntesten und frühesten Korpora, das British National Corpus BNC, umfasst 1994 2 Millionen Wörter (Tokens). Es galt (zu Recht) als Pioniertat und riesige Datenmenge.
Das Deutsche Referenzkorpus DeReKo umfasst im Januar 2025 63.8 Milliarden Wörter, also etwa 32.000 mal mehr als das BNC.
Was gross ist, ist also relativ...
Was genug gross ist, hängt vom Untersuchungsinteresse und dem zu untersuchenden Phänomen ab. Hier ein paar Hinweise dazu:
- Ein Phänomen, das sowieso sehr häufig im Sprachgebrauch vorkommt, findet sich auch in einem relativ kleinen Korpus. Fürs Deutsche typische Abfolgen von Wortarten wie Nomen, Artikeln, Adjektiven und Verben können selbst in einem wenige Texte umfassenden Korpus empirisch untersucht werden.
- Umgekehrt verhält es sich für Phänomene, die eher selten sind. V2-Stellung in Nebensätzen in Zeitungssprache ist (bis heute) ein eher seltenes Phänomen. Um untersuchen zu können, was typische Umgebungen oder Bedingungen sind, dass dies trotzdem vorkommt (z.B. im Rahmen von Interviews), bedarf es sicher eines sehr viel grösseren Korpus.
- Relevant ist immer auch, für welchen Bereich von Sprachgebrauch Untersuchungen gemacht werden sollen: Für Zeitungssprache ist es relativ einfach, umfangreiche Korpora zu nutzen, weil die Texte in bestehenden Korpora zur Verfügung stehen. Im Gegensatz dazu stehen persönliche Instagram-Messages: Solche Daten sind schwer zu beschaffen. Hier wird man sich gewzungenermassen mit kleineren Korpora begnügen müssen – und dabei im Blick haben, dass diese nur für einen beschränkten Teil von persönlicher Instant-Messaging-Kommunikation stehen können.